Seedance 2.0
Multimodal AI video creator that combines text, images, clips, and audio
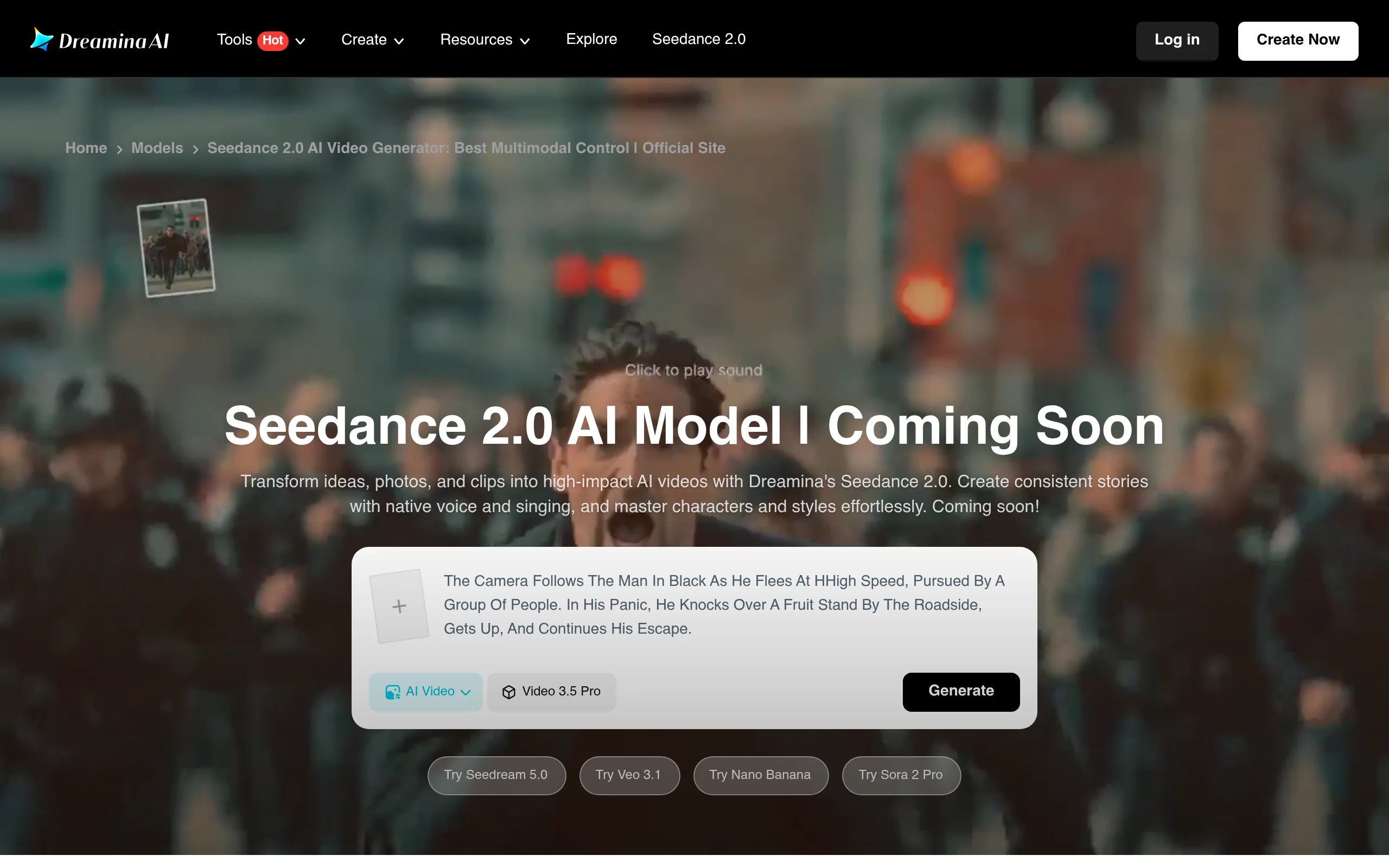
About Seedance 2.0
Overview
Seedance 2.0 is Dreamina's multimodal AI video model for turning ideas, photos, and clips into cinematic videos with unified style and character consistency. Official messaging highlights support for image, video, audio, and text inputs, with native voice and singing generation capabilities. The model page is live and marked as coming soon, with a free start entry point on Dreamina.
Key Features
- Official positioning is clear around multimodal video generation.
- Supports combined text, image, video, and audio inputs in one model experience.
- Highlights native voice and singing generation for richer storytelling.
AI writing platform for marketing content
Can your machine run AI models? Browser checker for local AI hardware
AI website generator and small business platform
All-in-one AI visual editing platform for image and video workflows
AI character platform for games and interactive apps
Public AI leaderboard and model comparison platform